浏览器渲染原理
浏览器渲染原理
Kaede引言
渲染原理, 其实就是 HTML+CSS+JS 的原理, 是浏览器的核心知识.

然而, 这些东西都及其的复杂, 不过就算只了解一部分, 也已经优于大部分的人了.
浏览器是如何渲染页面的
什么是渲染
渲染, render. 在 Vue 或者 React 中, 是通过渲染虚拟 DOM 来绘制页面的. 无论如何, 前端中, 渲染的意思就是将 HTML 字符串, 转换为屏幕上看到的页面信息.
我们访问网页, 其实拿到的是一个字符串, 格式是 HTML 的格式而已. 我们分析字符串, 才知道页面上的每个像素点的颜色是什么, 进而得到整个能够看到的页面.
同时, 鼠标滚轮滚动页面, 也需要重新计算. 渲染可以理解为一个函数:
1 | function render(html) { |
这就是渲染的本质.
渲染的时间点
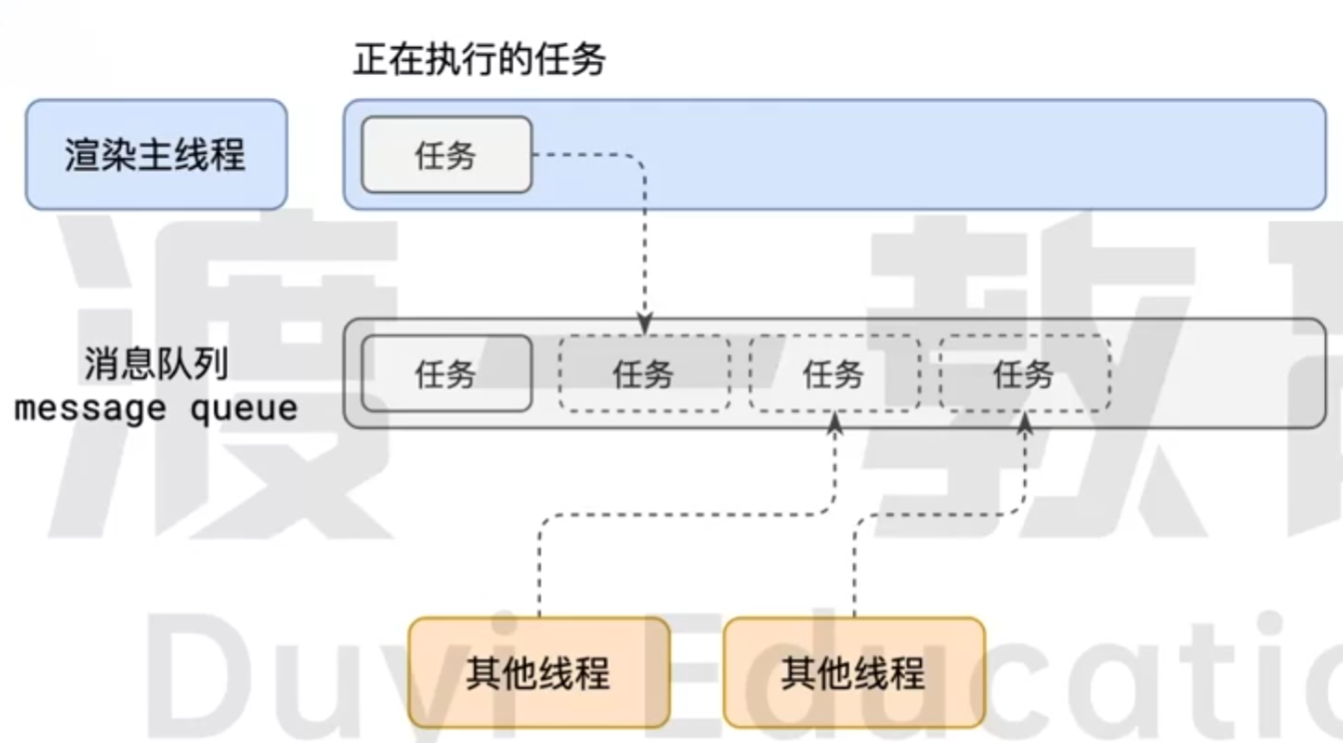
也就是在问: 什么时候进行渲染呢? 首先, 输入网址, 网络进程拿到了 HTML, 但是网络不能处理这个东西, 于是生成了一个渲染任务, 放入了消息队列中. 那么渲染主线程拿到了这个渲染任务, 开始进行渲染.
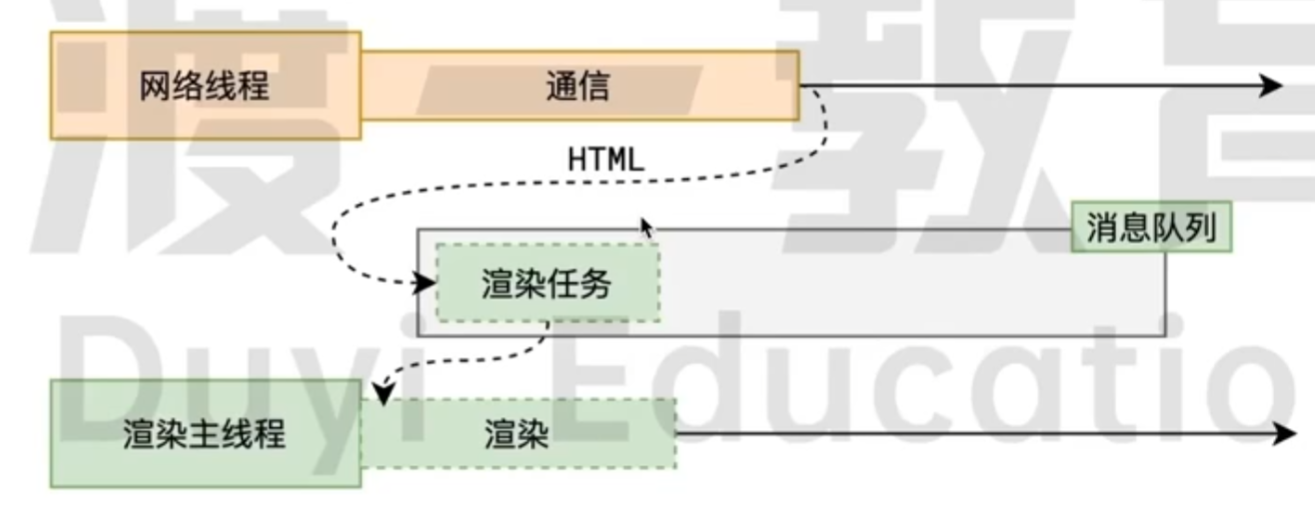
所以可以回答这个问题的第一点:
面试题: 浏览器是如何渲染页面的? Part 1
当浏览器的网络线程收到 HTML 文档后, 会产生一个渲染任务, 并将其传递给渲染主线程的消息队列.
在事件循环机制的作用下, 渲染主线程会取出消息队列中的渲染任务, 开启渲染流程.
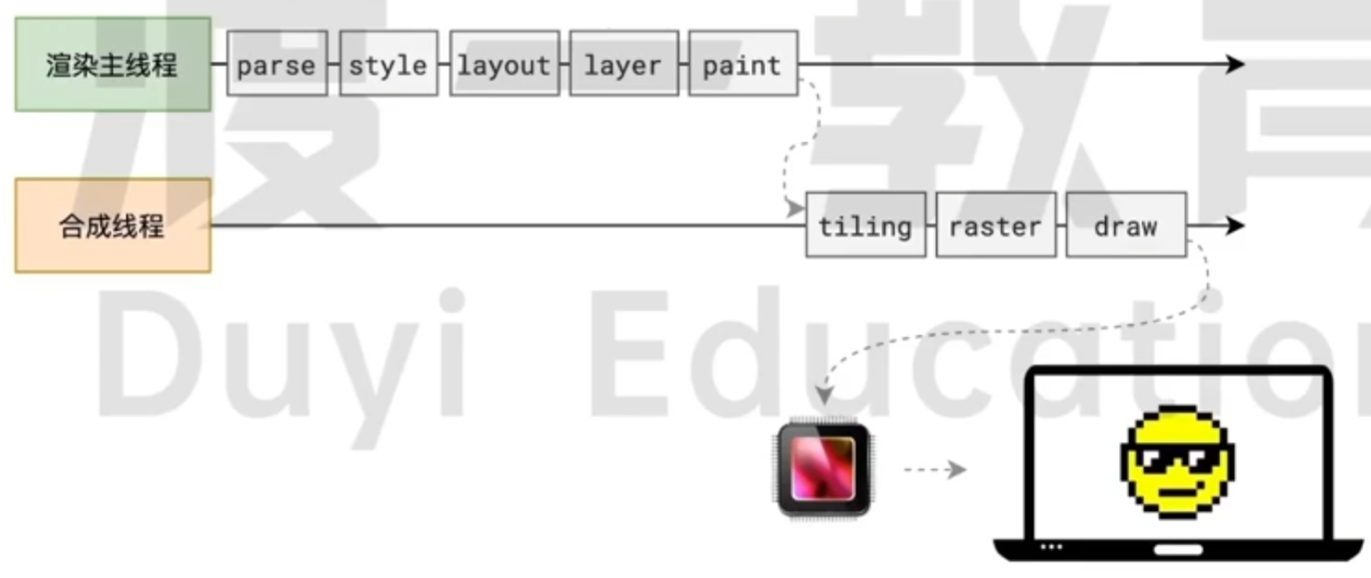
渲染流水线
流程就是下面这张图片的流程:
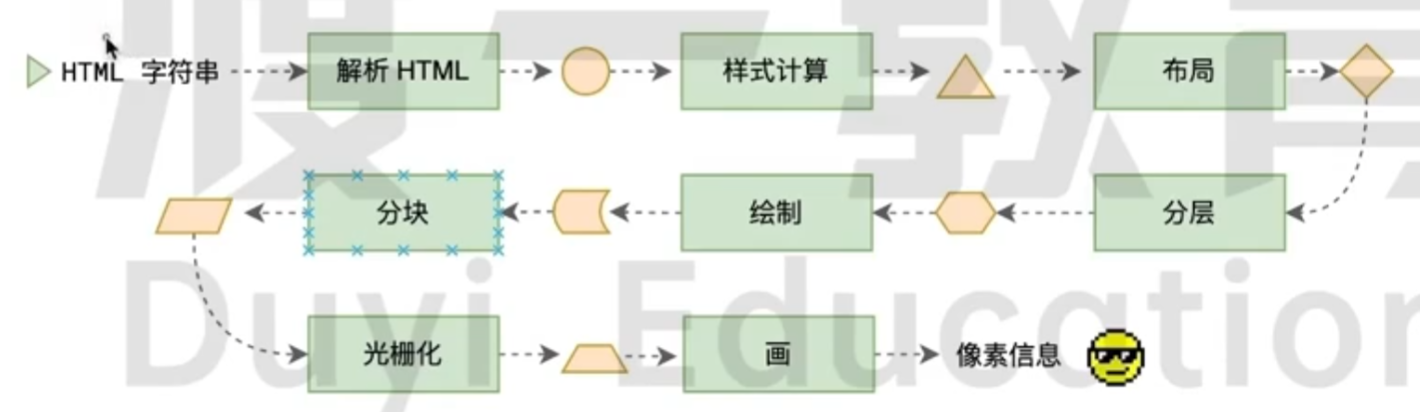
这就可以回答面试题的第二个阶段了:
面试题: 浏览器是如何渲染页面的? Part 2
整个渲染流程分为多个阶段, 分别是: HTML 解析, 样式计算, 布局, 分层, 绘制, 分块, 光栅化, 画
每个阶段都有明确的输入输出, 上一个阶段的输出会成为下一个阶段的输入
这样, 整个渲染过程就形成了一套组织严密的生产流水线
解析 HTML
解析 HTML
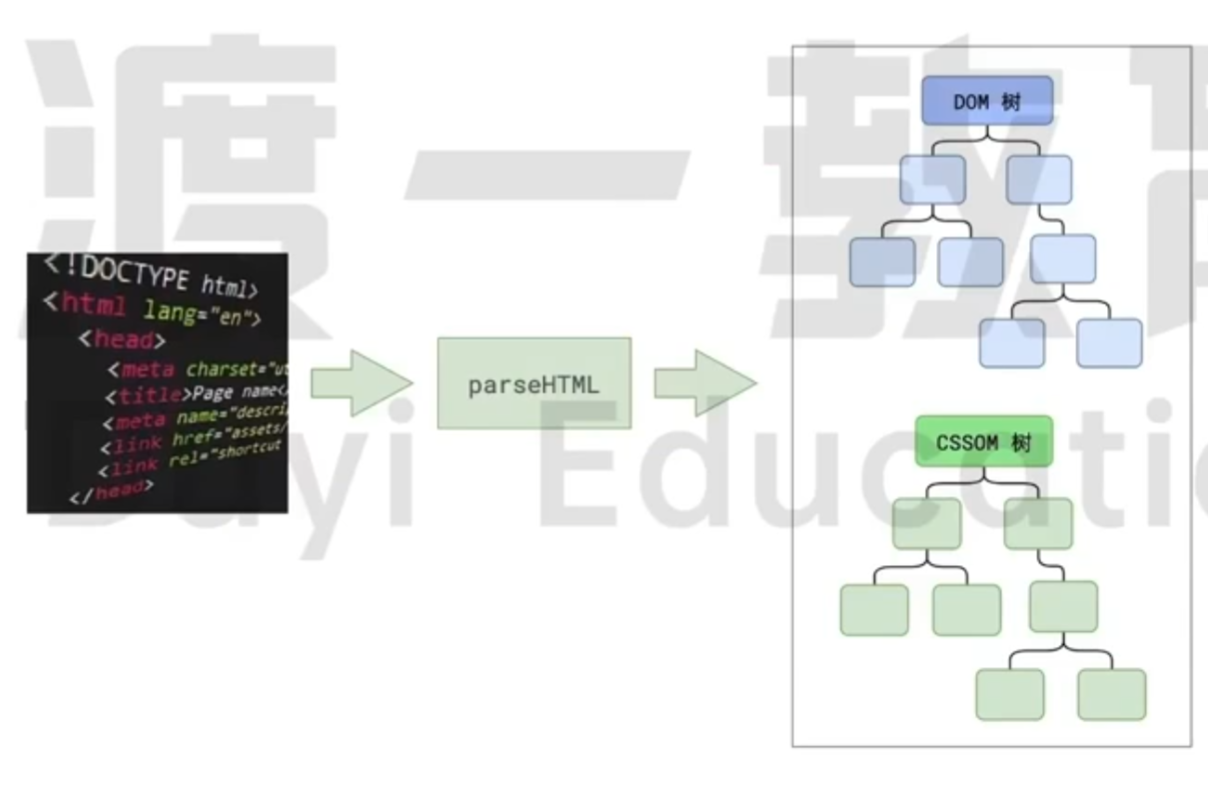
HTML 就是一棵树, 从根节点开始, 不断地进行拓展. 这里的节点其实就是 对象. document 其实就是一颗树. 如果在控制台进行查看, 可以看到类型为 object.
1 | typeof document |
在进行 JS DOM 操作的时候, 操作的其实就是这样的一个 DOM 树. DOM (Document Object Model). 在拿到字符串的 HTML 以后, 就会转换为这样的一个对象.
因为字符串的操作太过于繁琐, 所以我们使用一个对象来进行操作.
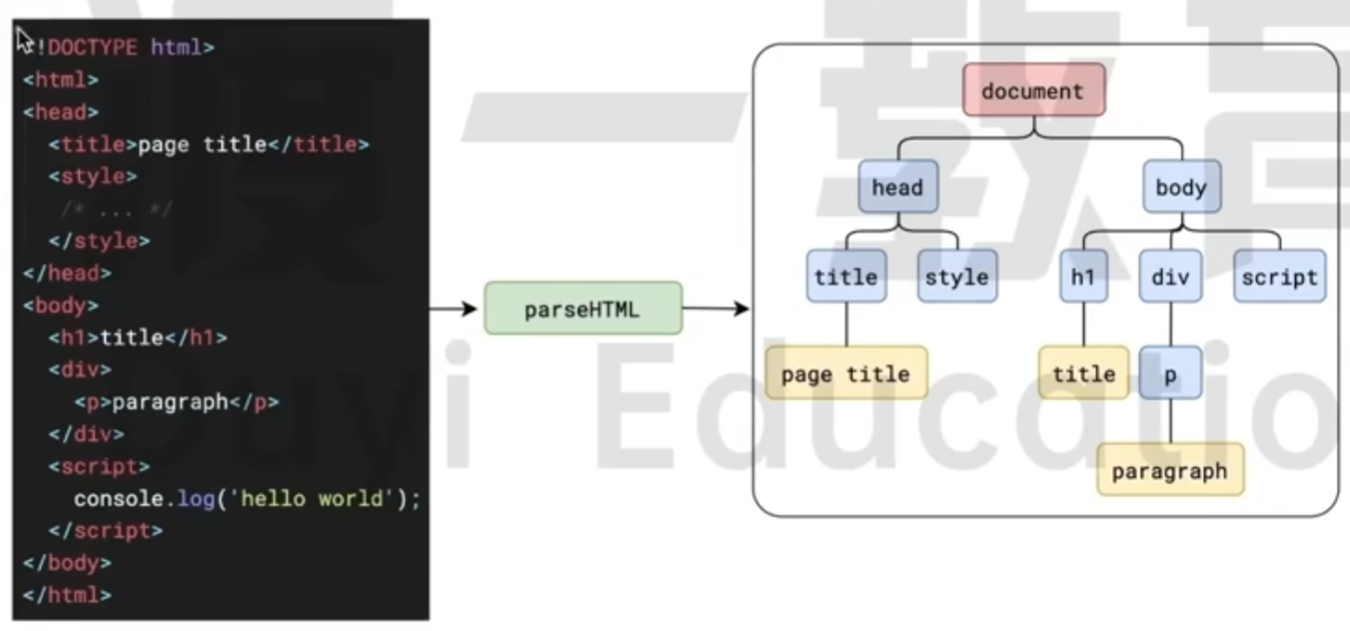
可以说, 这一步是为了后续的操作做准备的, 也给予了 JS 操作页面的能力.
另外, 对于 css 来说, 也会转换为一个树, COM (CSS Object Model).
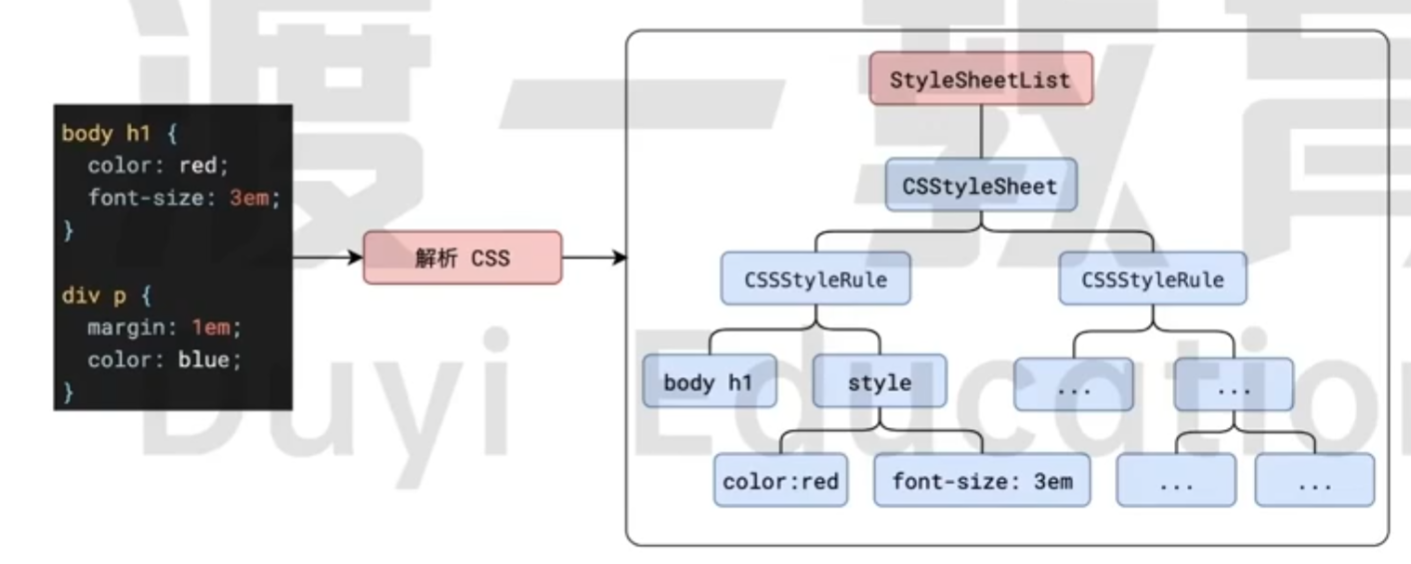
可以直接在控制台中查看:
1 | > document.styleSheets |
样式表分为了:
- 内部样式表
<style> - 外部样式表
<link> - 内联样式表
<div style="xxx"> - 浏览器默认样式表 (一开始, 每个元素都是有默认样式的)
每一个, 都会在根节点下面产生一个新的节点. 有一个, 节点就会多一个. 这些规则都会变成一个一个的规则对象, 规则的样式就是一个个的键值对.
JS 其实也是可以操作这些东西的. 只要修改上面获取的样式表, 页面就会发生变化.
这里还有一些细节需要注意:
HTML 解析过程中遇到 CSS 代码怎么办
为了提高解析效率, 浏览器会启动一个与解析器, 率先下载和解析 CSS
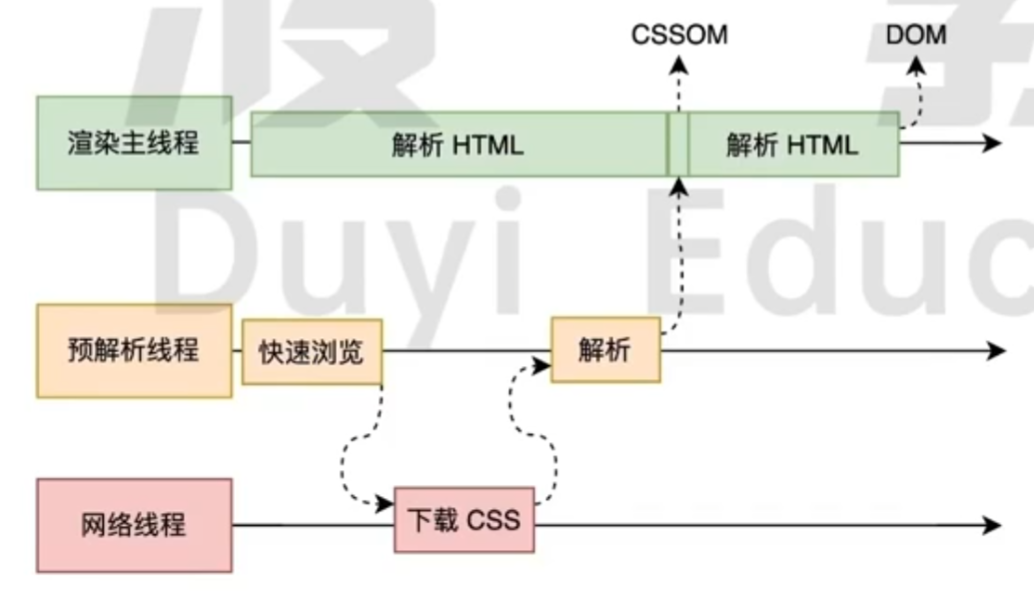
所以说, CSS 解析不会阻塞 HTML 的解析, 这两个东西跑在不同的线程上.
面试题: 浏览器是如何渲染页面的? Part 3
渲染的第一步是解析 HTML.
解析过程遇到 CSS 解析 CSS, 遇到 JS 执行 JS. 为了提高解析效率, 浏览器在开始解析前, 会启动一个预解析的线程, 率先下载 HTML 中的外部 CSS 文件和外部的 JS 文件.
如果主线程解析到
link的位置, 此时外部的 CSS 文件还没有下载解析好, 主线程不会等待, 而是继续解析后续的 HTML. 因为下载和解析 CSS 的工作是在预解析线程中进行的. 这就是 CSS 不会阻塞 HTML 解析的根本原因.如果主线程解析到
script, 就会停止解析 HTML, 转而等待 JS 文件下载好, 并且将全局的代码解析执行完毕后, 才会继续解析 HTML. 这是因为 JS 代码的执行过程可能会修改当前的 DOM 树, 所以 DOM 树的生成必须暂停. 这就是 JS 会阻塞 HTML 解析的根本原因.第一步完成后, 会得到 DOM 树和 CSSOM 树, 浏览器的默认样式, 内部样式, 外部样式, 内联样式均会包含在 CSSOM 树中.
JS 代码其实就执行一次, 点击或者计时器之类的事件都是别的线程在干的, 如果触发, 别的线程把任务放到任务队列就可以了.
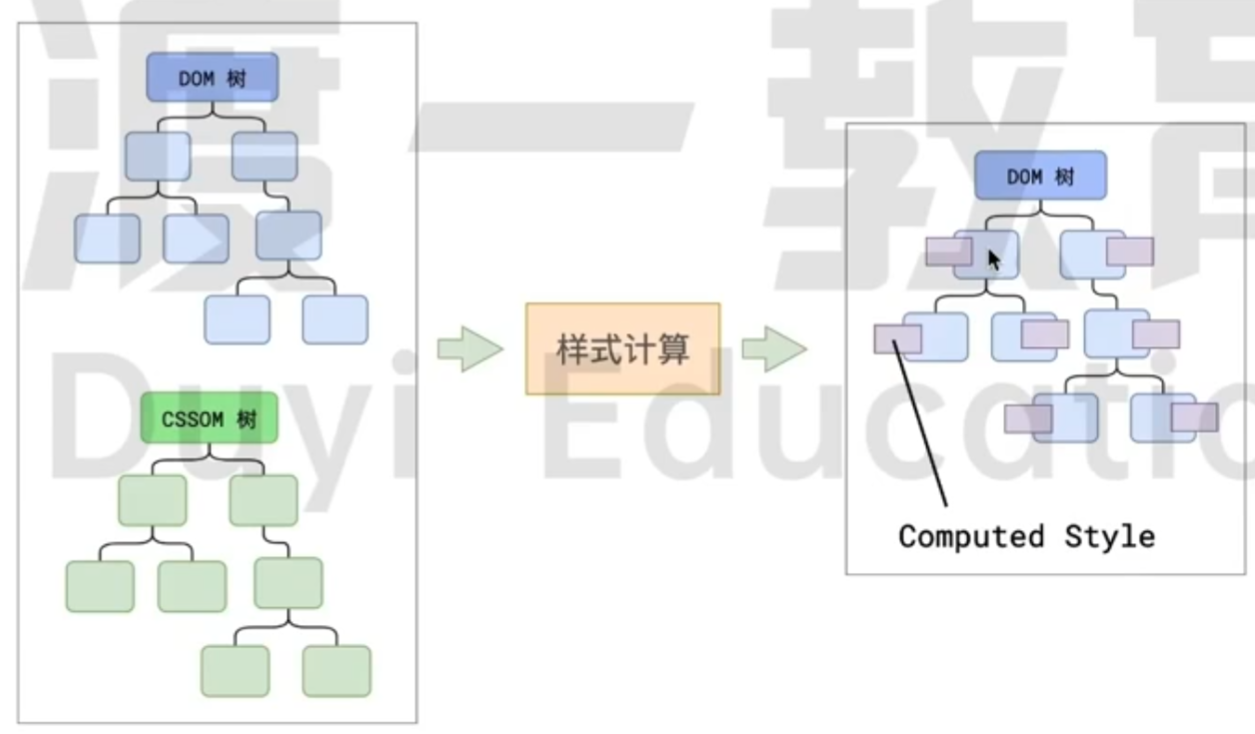
样式计算
样式计算
我们现在已经有了两个树, 但是我们需要把他们两个结合起来, 明确每个元素是什么样式. 这一步得到的就是最终样式了.
这里的最终样式不仅仅是我们写的样式, 还有许多默认的样式. 经过样式的计算, 我们的一个元素, 将会包含所有的样式属性, 并且每个属性都是有一个值的.
并且, 一些相对单位都会变成绝对单位. 所以响应式布局其实就是不断计算, 计算出来一个元素应有的位置.
面试题: 浏览器是如何渲染页面的? Part 4
渲染的下一步是样式计算.
主线程会遍历得到的 DOM 树, 依次为树中的每一个节点计算出它的最终样式. 称之为
Computed Style. 在这个过程中, 很多的预设值会变成绝对值, 例如red变成rgb(255, 0, 0); 相对单位会变成绝对单位, 比如em变成px.这一步完成后, 就会得到一颗带有样式的 DOM 树.
布局
现在有了样式和 DOM, 那么就可以根据计算出来的东西, 生成一个布局了. 这里其实很复杂, 因为一个父元素的样式发生变化, 那么子元素可能就会发生巨大的变化.
同时, 布局还需要应用各种规则, 比如字体大小, 盒子模型之类的.
无论如何, 计算结果很简单, 就是得到一个宽高, 以及一个位置. 这里的位置是相对于 包含快 的位置.
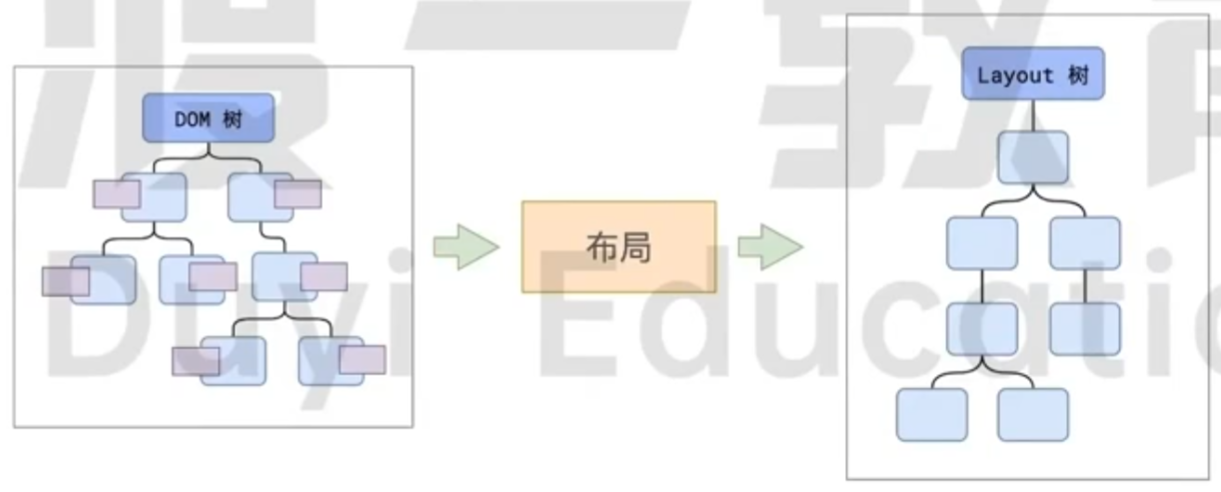
对于隐藏 (display: none) 的节点, 其实是不会被放在布局树里面的, 这也会影响元素的位置. 只要有盒子信息, 就会在布局树中存在.
下面这个也很重要:
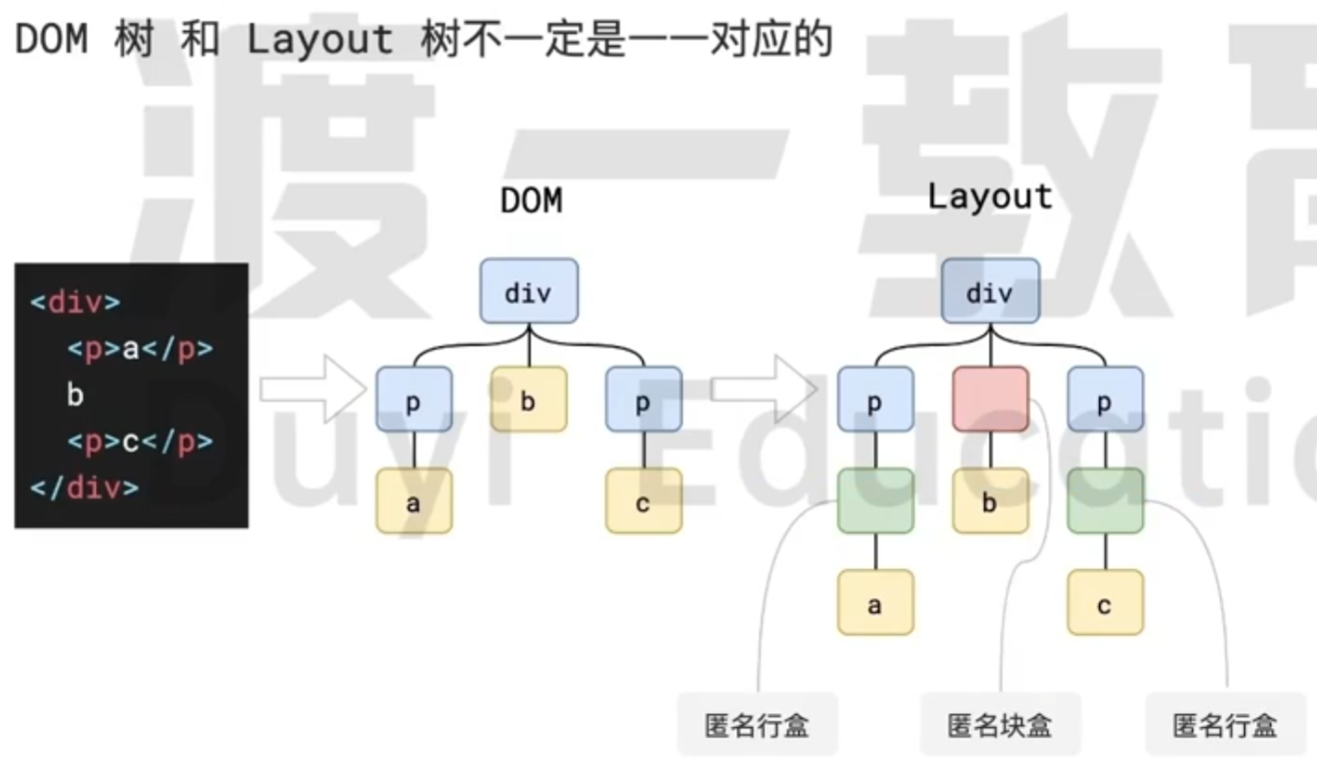
面试题: 浏览器是如何渲染页面的? Part 5
接下来是布局, 布局完成后会得到布局树.
布局节点会依次遍历 DOM 树的每一个节点, 计算每个节点的几何信息, 例如节点的宽高, 相对包含快的位置.
大部分的时候, DOM 树和布局树并非一一对应.
例如
display: none的节点没有几何信息, 因此不会生成布局树; 又比如使用了为元素选择器, 虽然 DOM 树中不存在这些伪元素节点, 但是他们包含几何信息, 所以会生成到布局树中. 匿名行盒, 匿名块盒等等都会导致这一问题.
分层
分层
页面画出来, 并不是完全静止的, 用户可能会有各种操作. 但是如果每次操作都重新绘制页面, 这样的工作量就太大了.
为了解决这个问题, 浏览器使用了分层的思想.

如果一个部分发生了变化, 只需要重新绘制那个层级就好.
当然, 层次不会太多也不会太少, 太多的话内存空间占用就会很大, 太少重新渲染也会不对. 每个浏览器, 甚至不同的版本, 分层的策略都是可能不一样的.
这里有一个挺有意思的: 如果页面上出现了滚动条, 其实滚动条也是一个单独的层级.
这里是不能手动的指定分层的, 但是可以给浏览器提供一个信息. 给一个元素添加 will-change 属性即可. 告诉浏览器这个元素可能会发生变化, 所以浏览器就会进行单独的照顾了.
当然, 还是取决于浏览器的决策机制.
面试题: 浏览器是如何渲染页面的? Part 6
下一步是分层
主线程会使用一套复杂的策略对整个布局树进行分层.
分层的好处在于, 将来某一个层改变后, 仅仅会对当前层进行后续处理, 从而提升效率.
滚动条, 堆叠上下文, transform, opacity 等样式都会或多或少的影响分层的结果, 也可以通过
will-change属性更大程度的影响分层结果.
无论如何, will-change 属性不要乱用, 除非感觉是分层产生的问题.
绘制
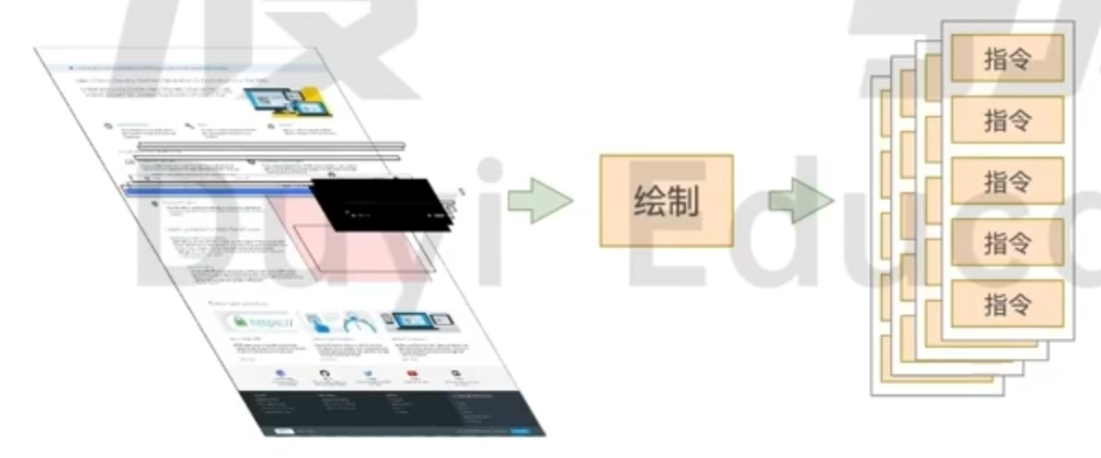
分块
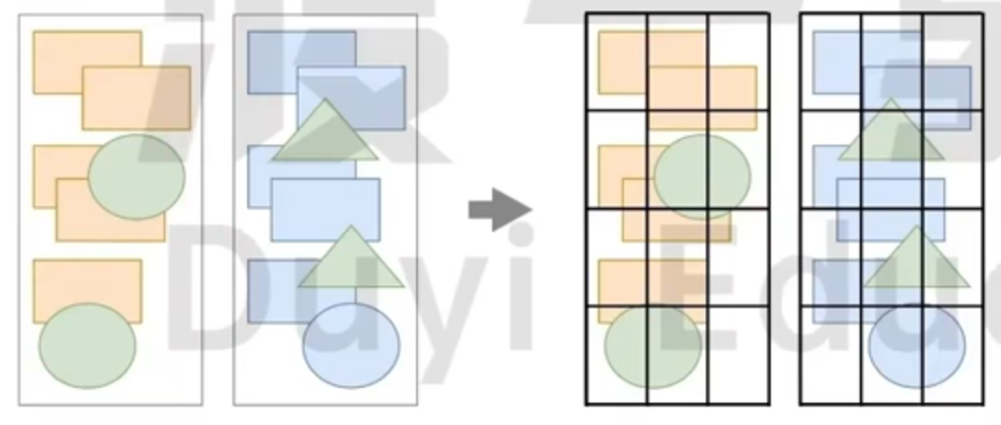
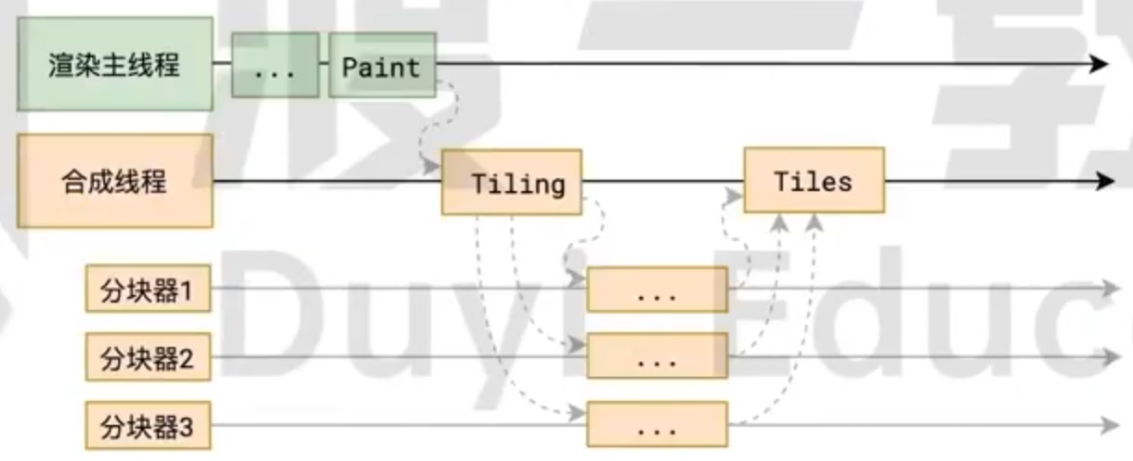
光栅化

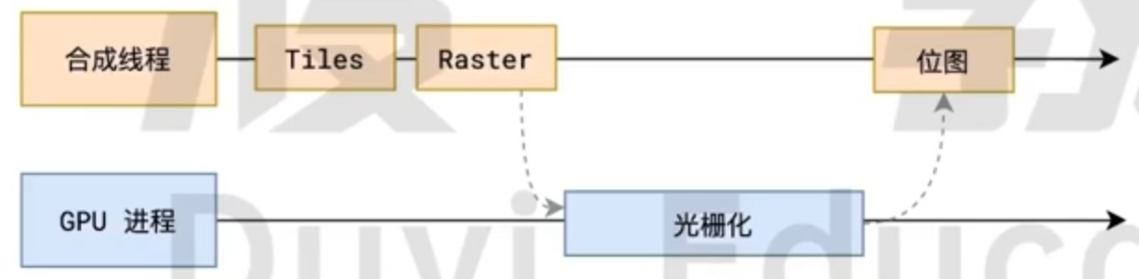
画
画
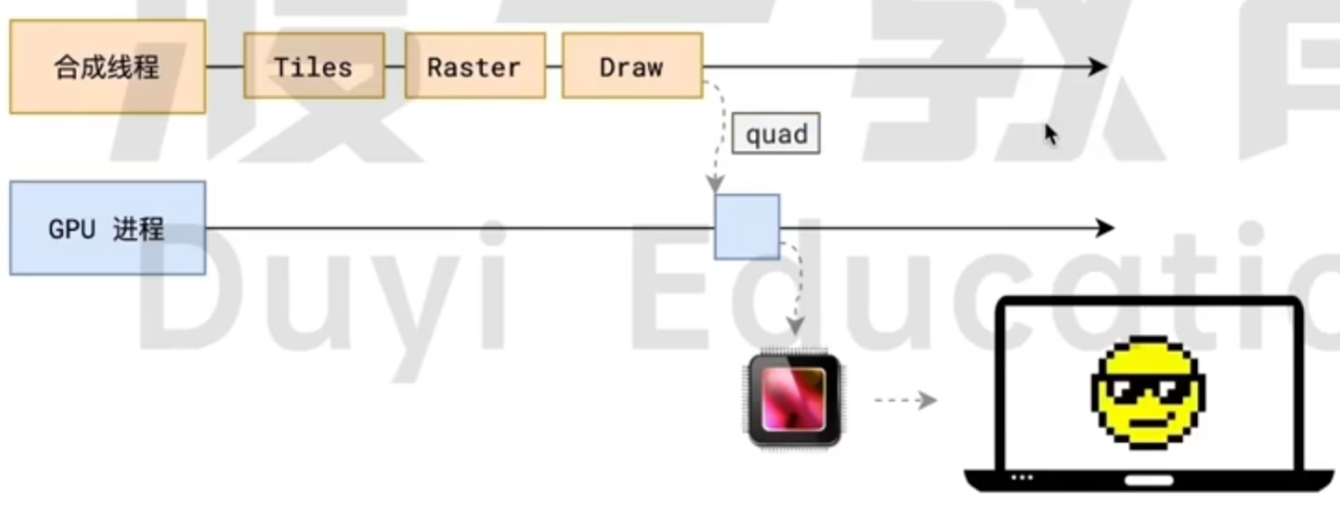
合成线程计算出每个位图在屏幕上的位置, 交给 GPU 进行最终的效果呈现.
下面这张图片中的 quad 就是一个指引, 然后 GPU 根据这个指引信息, 将任务交给真实的硬件, 硬件就可以得到最终的效果了.
这里的 GPU 进程是浏览器的进程, 合成线程是渲染进程的子线程, 相当于是一个沙盒. 这个时候, 浏览器是不能直接访问硬件的. 所以需要提交两次.
面试题: 浏览器是如何渲染页面的? Part 10
最后一个阶段就是画了
合成线程拿到每个层, 每个块的位图后, 生成一个个的 指引 (quad) 信息.
指引会标识出每个位图应该画到屏幕的哪个位置, 同时会考虑旋转, 缩放等变形.
变形发生在合成线程, 与渲染主线程无关, 这就是
transform效率高的本质原因.合成线程会把 quad 提交给 GPU 进程, 由 GPU 进程产生系统调用, 提交给 GPU 硬件, 完成最终的屏幕成像.
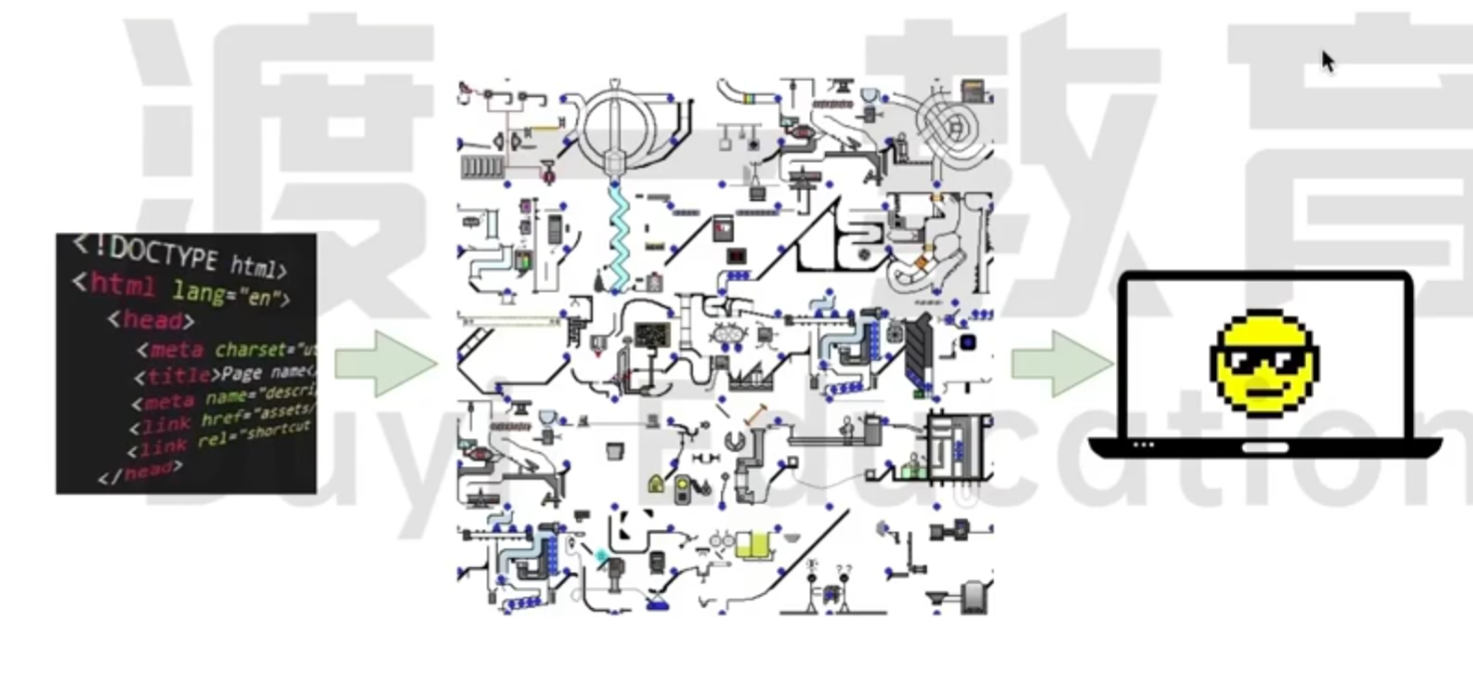
总结
其实就是下面这张图, 这就是 现代浏览器的完整渲染流程.